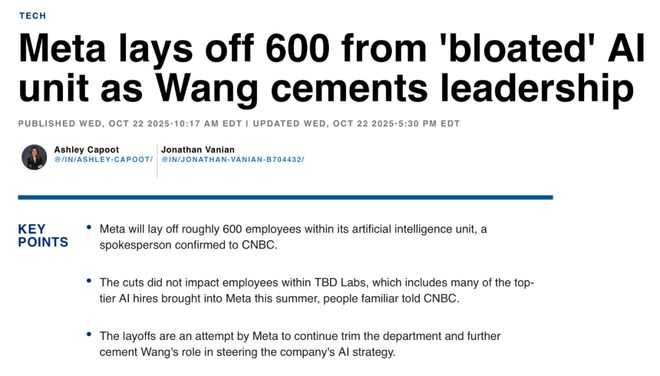
陈潜写道,2025年10月末,Meta AI部门宣布消失600个职位,甚至包括主部门的研究总监。与此同时,负责AI业务的高管辞职并被边缘化。即使是图灵奖获得者 Yann Lecun 也被认为无法保护自己。一方面,扎克伯格花费数亿美元年薪挖走AI人才,但同时,他在解雇员工方面也非常果断。这种分离背后的原因是什么?于是我们采访了AI科学家田元东、Meta前公平研究总监Gavin Wang、参与Llama 3后培训的前Meta员工、硅谷资深人力资源专家以及一些匿名人士,试图重述Meta的Llama OpenSource Ruta发生的事情:为什么Llama 3仍然让大家感到惊讶,而Llama 4已经一岁了?其间发生了什么? Meta的开源路线是否注定是一个错误酸?在人工智能大模型竞争激烈的当下,乌托邦式的人工智能研究实验室还能存在吗? (本文改编自视频,欢迎大家观看以下视频) 01 格奈Meta十年布局架构的诞生,我们来看看Meta对于AI布局的整个公司架构。 2013年底,扎克伯格开始组建Meta的AI团队。当时,Google 收购了 Geoffrey Hinton 的 DNN 团队并聘请了 Hinton。与此同时,Meta 邀请 Yann Lecun 监督人工智能的开发。至此,两大图灵奖巨头开始进军商业技术,引领AI研发。当扎克伯格邀请 Yann Lecun 加入 Meta 时,后者提出了三个条件: 1. 不搬离纽约; 2. 不辞去纽约大学的工作; 3.必须进行开放研究,所有所做的工作必须向公众发布,代码必须公开。因此,Meta路线由明星开源t。 Yann Lecun进入Meta后,开始从事前沿AI研发,并成立了AI主研究实验室,也被称为著名的Fair实验室,引领前沿人工智能研究。 Meta Basic AI研究(Fair)团队前研究总监田元东:Fair负责前沿研究,产生了一些目前看来没有特别大应用的新思想、新思路、瓦工算法、新框架、新模型架构。经过这样的探索,也许会有一些大的突破,大概就是这个逻辑。但对于meta来说,最终还是要在自己的产品中看到AI的发展。于是,与公平组平行成立了一个名为“Generative AI”的组,简称“Genai”组。该小组下设多个职能团队,包括LLAMA的开源模型研发和应用AI能力的META AI Team对产品的能力。还有AI算力基础设施的数据中心团队,还有其他的小部门,比如search(搜索)、business(商业服务)、video-gen model(文盛视频)等,他们就像一个天平,一边是前沿的科学分析,一边是劳动力。理想情况下,前沿研究可以带来更好的产品功能,从产品中赚钱可以让管理层更有动力公平地分配资金用于研发。 Meta Basic AI研究(Fair)团队前研究总监田元东:比如Fair会提供一些好的想法和工作给Genai使用,让Genai把这些想法和工作放到生产中,然后用在下一代模型中。很多人最初的愿望是做点别的事情,或者有不同的方向或工作。 AGI(通用人工智能)能否实现?这其实是一个相当大的问题。陈茜,Si联合创始人licon Valley 101:所以fair的目标是AGI,但Genai的目标是把AI放到Meta现有的产品中,让AI能够发挥作用。 Meta Basic AI研究(Fair)团队前研究总监田元东:对,应该说主要方面是Llama,Llama是一个非常大的模型。还有一个问题是如何在某些应用中最好地使用人工智能。然而,保持这样一种永远平衡的平衡,是一种非常理想的乌托邦状态。这种乌托邦状态的前提是,Meta 的 AI 模型水平始终领先,或者至少领先于开源赛道,而不会落后于闭源模型太远。图片来源:Meta Ai 硅谷101联合创始人陈茜:你觉得展会上最好玩的时候是什么时候? Meta Basic AI研究(博览会)团队前研究总监田元东:我觉得从参加博览会到2022年,这段时间是非常开心的。因为大语言模型到来之后,整个e生态学或者研究者之间的关系发生了一些变化。因为大规模语言模型出现之后,计算能力就成为了一个非常重要的因素。由于计算能力有限,就会出现各种问题和矛盾。每个人都要训练一个大模型。如果真是这样的话,那么彼此之间就会出现一些问题。比如说,我的牌很多,你的牌就少一些。因为没有太多的卡就没有办法训练出好的模型,所以2023年之后,状态肯定不如以前了。 Meta 的 AI 是如何平衡的?我们将从第四代Llama的发布中看到一些提示和线索。 02 《开源之光》前羊驼之傲和滑铁卢? Meta之所以将大语言模型命名为“llama”,据说是因为大语言模型的缩写“LLM”不太好读。只需添加元音即可。 “Llama”朗朗上口,容易记住。正是这样自此大型语言模型的命名就与“羊驼”联系在一起。 2.1 Lla??ma 1:开源的“种子” 我们先来看看 Llama 1,它也为 Meta 的大型模型“开源”路线奠定了基础。 2023年2月24日,Meta发布了LLAMA模型,主打“更小的参数和更好的结果”(多尺度:7B/13B/33B/65B),强调13B模型及时可以在许多基准测试中超越175B参数的GPT-3。 Llama 正式发布一周后,权重以种子的形式在 4chan 上“泄露”,引发了 AI 社区关于开源的广泛讨论,并促使国会参议员写信质疑元数据。虽然质疑的声音不少,但业界却出人意料地支持了 Llama 的“意外泄露”,这也被认为是对“大模型开源”格局的重塑,并迅速催生了众多民间修复项目。解释一下此处“开源”对于大型模型的含义。事实上,meta并不是完全开源的。 Meta 称之为“开放权重”。机器学习分为三个部分:架构、权重和代码。所谓“权重”就是模型学习到的所有参数值。完成模型训练后,lahat参数将保存在几个大的二进制文件中。每个文件存储神经网络各层的矩阵值。在推理过程中,模型代码将加载这些权重文件并使用GPU执行矩阵运算来生成文本。因此,“开放权重”意味着向公众提供训练好的参数文件,可以在本地加载、部署和修复,但它并不是完全“开源”,因为真正的开源意味着产生训练数据、代码、许可证等。不过,Meta 并没有透露这些信息。即便是后来的Llama 2、3、4代也只开放了重量,但许可政策却相当宽松。虽然LLAMA是“半开源”的,相比OpenAI,Anthropic和Google是完全闭源的公司,仅通过API接口提供服务能力,这给开源社区带来了巨大的活力。第2.2章 Llama 2:开放并“商用” 2023年7月28日,Meta和微软发布了LLAMA 2的大模型,其中包含7B、13B和70B参数三个参数变体。虽然新一代模型的“开源”也有“开放权重”,但相比于 LLAMA 1 尚未商用,只能用于研究目的,LLAMA 2 是免费且商业的版本,放宽了许可权限。 《连线》等杂志甚至指出,《Llama 2》走的是“开放路线”,对抗现实中封闭的巨型模型。我们看到,Llama 2已经迅速在开发者社区流行起来,它的存在极大地推动了生态和人工智能的发展。后那么,到了2024年的《骆驼3》了,这也是骆驼系列最辉煌的时刻。第2.3章 Llama 3系列:来到闭源阵营,进入LLAMA3时代,Meta已经成为AI开源社区的领军存在。从2024年4月到2024年9月,Meta将发布模型的三个版本迭代。 2024 年 4 月 18 日,Meta 发布了 Llama 3 两种规格的版本:8B 和 70B,称这两种尺寸“明显超过 Llama 2”,并将其作为 Meta AI 助手的基础之一。 7月23日,Meta推出了三个级别的LLAMA 3.1型号:405B、70B、8B,并声称405B是“最强大的开放可用的核心型号”之一;它还已在AWS Bedrock、IBM Watsonx等平台上推出。仅仅两年后,2024 年 9 月 25 日,Meta 推出了 LLAMA 3.2,专注于小而全的多模态模型,增加了 1B 和 3B 轻文本模型以及 1B 和 90B 视觉多模态模型,专注于终端/边缘场景; AWS等平台可以同时访问,开源的Ollama平台也可以本地运行。我们采访了 Llama 3 团队的 Gavin Wang,他负责 Llama 3 的后期训练工作。他告诉我们,整个 Meta 和 Genai 团队当时都在以“光速”前进。真的感觉就像“人工智能的一天,人类世界的一年”。前Meta Ai工程师Gavin Wang曾参与Llama 3的后期训练:那段时间,LLAMA 3.1/3.2取得了很多不错的进展。比如这个阶段发布了多模态,后来又做了轻量级的1B/3B模型。我感觉生产力生态系统此时已经取得了很大的进步,并且有很多支持的社区,包括我在 LLAMA Stack 团队的朋友,他们致力于支持整个 LLAMA 生态系统在企业层面或小型企业层面的实施。 LLAMA 3的强大攻击力,特别是450B版本,在模型能力上被认为接近闭源阵营,也被认为能够快速推动AI应用的落地。对于Meta的内部员工,尤其是LLAMA集团的AI工程师来说,这是一个让他们感到自豪的项目。前Meta人工智能工程师Gavin Wang参加Llama 3后培训:当时的说法是,meta是各大厂商留下的唯一开源模型,它在整个开源生态中也做出了很大的贡献。当时,我想很多人都觉得这不仅仅是工作,而是我们真正支持了整个人工智能前沿的发展。你所感受到的一切都是非常有意义的。我当时非常自豪。当我出来告诉别人我在 LLAMA 3 团队工作时,一些 Startup 创始人会说:非常感谢你们的努力。感觉整个科技圈,尤其是AI创业圈,都在指望LLAMA。摆脱借助东风,Meta 希望 LLAMA 4 的发布能够进一步扩大其在 AI 开发社区的影响力,并保持“领先大型模型的唯一开源可用性”。扎克伯格在 2025 年 1 月底的财务报告会议后发帖称,“我们 LLAMA 3 的目标是让图书作为源代码和封闭模型具有竞争力,我们 LLAMA 4 的目标是领先。”然而,三个月后《Llama 4》的发布却是一场彻头彻尾的灾难和滑铁卢。 2.4 Llama 4:滑铁卢 2025 年 4 月 5 日,Meta 推出了 llama 4 的两个版本(scout 和 maverick),声称多模态和长上下文能力得到大幅提升,并高调提到 llmarena 排名中的领先成绩:maverick 版本仅次于 Gemini 2.5 pro,与 Chatgpt 4O Grok 3 Pro 并列第二。不过,开发者社区的反馈并不积极,认为Llama 4的效果没有预想的那么好。茹mors开始在市场上流传,meta版本在Lmarena达到了第二名。 Llama 4疑似用优化后的变体欺骗了llmarena,而这个变体接受了对话增强训练,误导了llmarena并导致过拟合。尽管 Meta 的高级管理层很快否认作弊,但影响很快蔓延开来。一方面,媒体认为“用专门调整的版本提升排名”是“诱饵”,业界对基准可信度和再现性的讨论升温。另一方面,更高端的庞然大物版本Meta推迟发布,引发了严重的公关和节奏剧变。到目前为止,Behemoth 还没有发布,也许 Meta 已经放弃了。众所周知的是,扎克伯格开始孤注一掷,让人工智能规模化,挖来亚历山大・王(Alexander Wang)领导新的人工智能架构,然后开始挖人,动用数亿美元。美元支票,疯狂扰乱硅谷人工智能人才市场。然后就是最近的新闻了。 Alex开始重组Meta的整个AI架构并解雇了600人。但如果你看这个时间线,是不是还是觉得很碎片化呢?美洲驼 3 和美洲驼 4 之间这一年发生了什么?为什么 Llama 4 突然停止工作?是不是太快了?通过分析,我们或许找到了一些答案。还记得我们之前提到的元内的AI架构是一个尺度吗?骆驼4失败的原因是:天平失去平衡。 03不平衡平衡的前沿研发Meta的AI架构中的商业化路线之争,patas和Genai是两个相似的群体。 Yann Lecun 负责管理展会,但 siYann Lecun 却花了很多时间沉浸在自己的研发中。有时他也在网上和人比拼肌肉,经常说不看好LLM溃败e,这让Meta很头疼。因此,2023年2月,Meta AI高管将Meta AI的研究总监Joelle Pineau调往展会,担任展会全球负责人,与Yann Lecun一起领导展会。图片来源:Business Insider Genai 的负责人是 Ahmad al-Dahle。这位朋友在 Apple 工作了近 17 年。扎克伯格之所以带领他,是将AI融入到各种Meta产品中,包括Metaverse、智能眼镜的AI集成、聊天工具meta.ai等。在经历了Llama 2的成功以及公司开始开发LLAMA 3之后,Meta高管越来越强调“将AI用于自己的产品”的本质。所以我们看到,2024年1月,Meta的AI团队进行了重组,两位展会领导开始直接向CPO(首席产品官)Chris Cox汇报。前Meta Ai工程师Gavin Wang从事llama 3后期训练: llama 1~3整个时期是大家为sc疯狂的时期阿令法。当时整个行业都跟着基础模型能力的提升。大家探讨了基础模型和大语言模型本身的能力极限。但 Meta 的领导层,如扎克伯格和 CPO Chris Cox,很早就意识到大型语言模型的功能可以得到实施并真正为社会创造价值。他们应该是从产品实力的角度出发的。所以在Llama 2和Llama 3阶段,整个Genai的主要目标是让研究成果真正具有生产力和工程化。因此,在高层管理人员中,包括副总裁和高级总监,他们都是由具有更多产品和工程背景的人领导。 LLAMA 3 成功推出后,高管开始制定 LLAMA 4 的元时,所有注意力都放在产品集成上,即多模态能力上,因此强调推理能力事实被忽略了。在从 LLAMA 3 到 LLAMA 4 长达一年的研发过程中,2024 年 9 月 12 日,OpenAi 推出了基于思想链的 O1 系列模型。随后在2024年12月,中国开源模型问世,采用MOE Hybrid Expert架构,在保证推理能力的同时,大幅降低G模型成本。硅谷101联合创始人陈潜:在你受邀发布《骆驼之火4》之前,你在忙什么? Meta Basic AI研究(Fair)团队前研究总监田元东:我们这里正在做一些推理研究。主要是对连锁思维做了一些研究,包括方法和训练方法。 O1于去年9月推出。事实上,在O1出来之前,我们就注意到一个很长的思想链会对整个模型的标度律产生影响。图片来源:ARXIV 事实上,在博览会组里,田元东等研究者已经在进行思路链的研究,但这样的探索推理能力没有及时传递到 LLAMA 模型项目中。 Gavin Wang,前 Meta AI 工程师,看过 llama 3 后的培训部分:在规划 LLAMA 4 时,我感觉到这里的领导方向可能会发生一些变化。我觉得总的来说,他们还是想支持Meta本身致力于推广的一些产品,也就是Llama自己的生态,多模态肯定是要点之一。但 Deepseek 一月份就出来了,他们的推理能力很强。推理能力也是当时讨论的方向之一,但由于Meta本身的生态,他们更关注多模态而不是推理。但是Deepseek出现的时候,我当时其实已经离开了llama团队,不过据说他们正在讨论是否要重新拿下识别区域。但在这方面可能会存在一些优先级上的冲突,而且时间也有限,导致加班加点、多次尝试,这使得h 很忙。我想 Deepseek 的出现一定造成了公司内部资源管理和优先级的一些混乱。还有一点,我认为llama 1到3整个模型结构和组织结构是一开始设计的延续。但由于Llama 3的成功,大家都期待Llama 4能走得更远,做一些更大的项目。这个时候可能会出现一些问题。我的观察是,在公司的高层,如副总裁和高级总监,他们中的许多人拥有更传统的基础设施和计算机背景,也许更少的自然语言处理背景。所以可能他们在技术层面对原生AI或者大科技语言模型这样的东西并没有深入的理解和理解。那些真正知道自己在做什么的人可能是一些博士。下面做具体的事情。我们特别自豪的是,中国博士生。都很有科技感听起来很合乎逻辑。但他们在公司内部没有发言权或资源。因此,由于某种未知的原因,可能会出现一些外行管理专家的情况。图片来源:Deepseek 由于 OpenAi 的 O1 系列和 Deepseek 的出现,Meta 在 2025 年初陷入了混乱。随后,Fair 的顶级研究团队管理层临时要求支持 LLAMA 4 的研发,或者可以直接说“救火”,而这个“救火团队”是由田元东领导的。Meta 基础 AI 研究(Fair)团队前研究总监田元东:关于地板我现在有一个很大的教训就是,做这样的项目的时候,不能让不懂的人做整个领导,或者做整个策划,如果出问题了,大家应该说:好吧,我们这个时候不能发布,我们推迟一下吧,这应该是我可以推迟发布,直到完成并且可以正常工作的方式,不能说提前定了期限。很多事情都无法正确完成。我想我们团队里的很多人当时都很累。例如,我在加利福尼亚州,因为我的许多团队成员都在东部时区。中午12点他们给我打电话。那里已经是下午三点了,他们还在工作,所以非常困难。他们为什么这么努力工作?这是因为期限很紧。比如我们的deadline是某天要发布的计划,项目管理就需要来来回回,然后看看2月底或者3月初需要做什么,3月底需要做什么。但是如果你做了这些事情,你发现模型在这方面不好,或者数据有问题,在这种情况下,我认为一个很大的问题是,你怎么能因为你的话而停止一切。比如我说这个数据有问题,不行,我的数据不能用,我们得改。如果发生这种情况,就会出现更多的问题,我们会整个事情必须推迟一两周。但能否做到却是一个大问题。如果在期限的强大压力下,最终的结果是这件事情做不成,或者大家都没有办法提出反对意见,那么最终的质量就会很差。这是一个相当大的问题。硅谷101联合创始人陈潜:为什么Meta的截止日期压力这么大?由于开源模型,它确实是第一。当然,年初Deepseek问世时,没有人预料到。但为什么它有一个严格的截止日期,要求我必须在这个时候推出这个东西? Meta Basic AI研究(公平)团队原研究总监田元东:应该说是有上级规定的期限,但是我不方便讲。也许你应该问问相关人士,他们就会明白。图片来源:Meta 我们通常在这里有一些答案。从 Llama 3 开始,“产品勾勒出了“AI化AI”路线。整个模型注重多模态和应用,忙于融合应用和业务,却忽视了目的性和更多的研究和技术开发。这迫使天平另一边的公平团队向团队“放火”。这样,平衡就失衡了。ETA基础人工智能研究(公平)团队前研究总监田元东:但实际情况是,切割模型的竞争太激烈,所以真正使用一些模型确实很难。虽然有些文章已经被使用了,但是我们的沟通过程中仍然存在一些问题。我在展会上有时会向Genai的人发送信息,但他们不理我。但是我去了Genai后,我感觉我无法真正处理他们(Fair研究员)。因为我很忙,例如,如果我半小时不查看我的手机,我可能会收到20或30条消息。读,很多人要寻找,很多事情要决定。所以我明白,在 Genai 这样的环境中,很难有更长的思考过程。扎克伯格是如何解决这种不平衡的?他直接空降了一支特种部队:由亚历克斯・王(Alex Wang)领导的TBD小队。 04 空降“新王” 28岁的Alex Wang在Meta人工智能业务架构重组后获得“无限特权”,高层也经历了一系列风波。 Alex Wang带领数十名高薪聘请的顶尖研究人员独立成立了TBD,这是一个在元内拥有无限特权和优先级的特殊群体。 TBD、Fair 和 Genai 共同组成元超级智能实验室(MSL 部门),直接向 Alex 汇报,Alex 直接向扎克伯格汇报。这也意味着Fair的Yann Lecun现在也向Alex汇报,而Joelle Pineau则被要求向Genai集团负责人Ahmad汇报。我们看到 Joelle 在今年 5 月离职,前往 Cohere 担任首席人工智能官;老实说,艾哈迈德已经沉默了很长一段时间,没有被指派监督任何重要项目;而CPO Chris Cox也被抢了Alex的风头,被排除在AI团队的直接领导之外。所以目前的结构是28岁的Alex占主导地位。我们在 Meta 内部听到了 Alex 和他领导的过度特权团队的各种抱怨,包括 TBD 团队的人员三年内不必进行绩效评估,他们可以忽略其他 VP 信息,所有 Meta AI 论文在发表之前都必须经过 TBD 人员的审核。你知道,很多TBD的人都很年轻,这让很多年长的研究人员不高兴。尽管如此,各种内部政治斗争似乎又要开始了。但不可否认的是,特权背后的等号已经实现了。对于扎克伯格来说,这次成功不仅会让美洲驼再次伟大,而且“元必须获胜”(meta Must win))。在本次人工智能大赛中,当前的重组可能是扎克伯格最后也是最重要的机会。 Alex在团队内部邮件中写道,他将做出三点改变:1.关注TBD的核心研究能力和公平的团队; 2、提高研究与产品开发和应用的融合,继续以产品为典范; 3. 建立核心基础设施团队来支持研究投入。硅谷资深人才专家Tom 张:第一是让基础研究、TBD Lab、fair更加有感情,让他们融合得更紧密。因此,此时放下的一些研究人员也在电子邮件中表示,他们的项目可能不会产生如此高的影响。你可以做一些剪切研究,但是这和我们今天没有任何关系,因为很多剪切研究是非常抽象的,从数学的角度,从很多理论的角度来看,它离工程真的很远。二是产品与模式融合更加紧密。Alex Wang 的加入者之一是 GitHub 的原 CEO。这意味着倪扎克伯格同时引进了两名高端人才,一个是Alex Wang,一般负责模特;另一个是Alex Wang。另一位是GitHub前CEO Nat Friedman,他更专注于产品,因为产品可以为模型提供更好的反馈,并在使用过程中产生飞轮效应。三是建立统一的核心基础设施(Infra)团队,更好地集中管卡的数据中心团队。以前大概是分散的,只有几个领导在场。如果你想被困住,你就必须申请。现在发卡实行统一管理。所以这封电子邮件非常清楚。如果亚历克斯能够兑现扎克伯格的赌注,我们可能很快就会得到答案。图片来源:Business Insider 综上所述,Meta 仍然是 LLAMA 前三代中领先的开源模式,带领开源派对抗闭源派等Openai 和 Google Gemini。然而,在 LLAMA 3 取得巨大成功后,公司高层迫切希望将人工智能融入到生产中。在规划路线时,他们采用“产品驱动研发”的思维,将LLAMA 4的升级重点放在多模态等工程性能上。然而,他们错过了思想链(COT)等尖??端推理技术的时间优势。虽然当时田元东等fair的AI科学家已经在COT进行研究,但在Deepseek引起轰动后,田元东Fair的Team暂时被放出来,去优化llama 4中的MOE架构。反而中断了cot和inference的研发,导致aof对AI前沿技术研究和产品工程的平衡完全不敏感。采访过程中,我不止一次想到历史上曾经闪耀过一段时间的尖端实验室:贝尔实验室、IBM Watson Research、HP Labs等。 FA、w有着十多年历史的IR,曾经是一群理想化人工智能科学家的乌托邦,如今却成为商业化的又一个牺牲品。您认为由《llama 4》的失败引发的这次重大重组是Meta AI的最后机会吗?欢迎在评论区留言告诉我们。视频通过视觉和音乐进行了增强,更好地展现了故事的迷人细节。请跳转硅谷101【视频账号】观看完整版 注:部分图片来自网络【本节目不构成任何投资建议】【视频播放频道】国内:B站|腾讯|视频帐户 |西瓜|标题 |百家帐号 | 36克|微博 |虎秀海外:YouTube 联系我们:
[email protected] [主创团队] 主管 |洪军 撰稿/主持 陈茜|编辑 陈茜 |橙色动效|踢AK12操作|王子钦 孙泽平 何元庆
特别声明:以上内容(含照片或视频)ny)已由自媒体平台“网易号”用户上传发布。本平台仅提供信息存储服务。
注:以上内容(包括图片和视频,如有)由网易HAO用户上传发布,网易HAO为社交媒体平台,仅提供信息存储服务。





 推荐文章
推荐文章










